UE12 - pandas et matplotlib¶
Où on découvre les deux dernières bibliothèques socles de l’écosystème Python :
pandaspour la data-science (importation et mise en forme de données)matplotlibpour la visualisation de données, en abrégé dataviz
Et nous commençons par étudier les bases de pandas
contextualisons Python et les tables de données¶
Nous venons de voir quelques fonctions de base de la librairie numérique de Python numpy. Nous savons désormais faires des manipulations simples de tableaux np.ndarray qui sont des tableaux multidimensionnels, homogènes, d’éléments de taille fixe.
Revenons à notre introduction à numpy où nous avons vu différents styles de tableaux, la matrice que nous avons déjà bien manipulée dans les notebooks précédents, l’image que nous ne traiterons pas plus en avant dans ces cours introductifs, la série temporelle que nous ne verrons pas plus loin … attardons-nous sur les tables d’informations comme celle de 891 naufragés du Titanic, nous la montrons à nouveau:
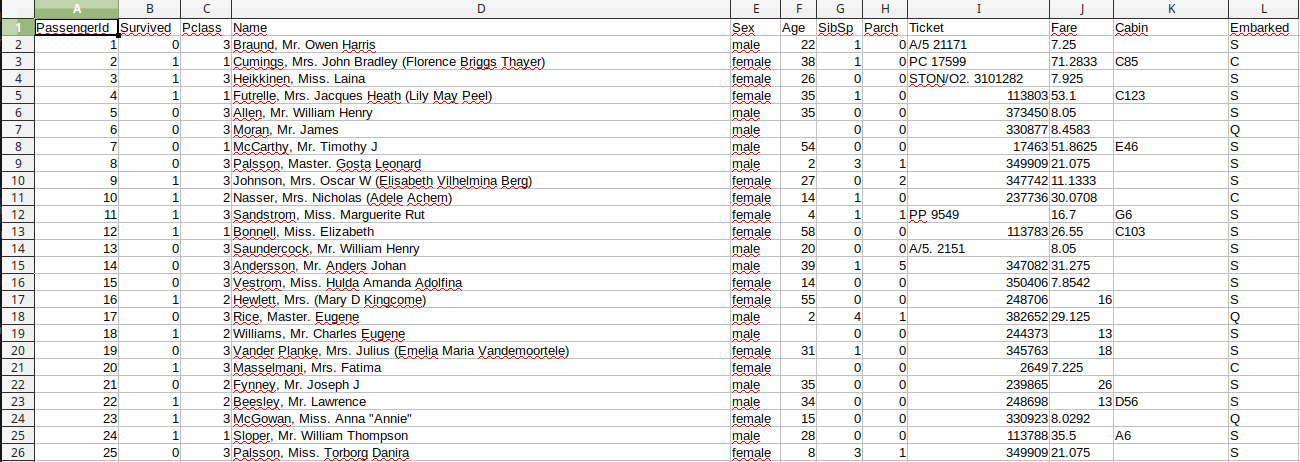
En ligne vous avez toute une série d’observations, une par ligne (ici les passagers du Titanic), et en colonne vous avez les 12 informations que nous savons d’eux, comme leur nom, leur âge, leur genre, leur classe de cabine, si ils ont survécu … quand on regarde la table chaque information forme une colonne.
Ce genre de tables sera très fréquent en data-science.
Pour les stocker en mémoire, vous pensez à un type particulièrement utile que nous venons de voir dans une librairie numérique … mais oui bien sûr un np.ndarray de dimension 2 et de forme (891, 12) !
Voilà nous savons quel va être le type de ces tables. Mais bien sûr, vous n’allez pas entrer ces tables à-la-main dans votre code (comme on l’a fait parfois pour nos matrices !) ces tables seront déjà décrites dans un fichier que vous allez simplement lire afin que son contenu soit transformé en une structure de données Python.
Quel est le format le plus simple pour ces tables dans un fichier ? Il suffit de mettre chaque observation sur une ligne et, dans les lignes, de séparer chaque information par un caractère choisi, toujours le même.
C’est ce qui a été fait: ces tables sont décrites dans des fichiers de type csv pour comma-separated-values, littéralement des valeurs séparées par des virgules. Ces fichiers porteront l’extension .csv ainsi la description de notre fichier de données du titanic a pour nom titanic.csv ! Gardons-le dans une variable!
file = 'titanic.csv'
Regardons le début de la table du Titanic:
PassengerId,Survived,Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarked
1,0,3,"Braund, Mr. Owen Harris",male,22,1,0,A/5 21171,7.25,,S
2,1,1,"Cumings, Mrs. John Bradley (Florence Briggs Thayer)",female,38,1,0,PC 17599,71.2833,C85,C
3,1,3,"Heikkinen, Miss. Laina",female,26,0,0,STON/O2. 3101282,7.925,,S
4,1,1,"Futrelle, Mrs. Jacques Heath (Lily May Peel)",female,35,1,0,113803,53.1,C123,S
5,0,3,"Allen, Mr. William Henry",male,35,0,0,373450,8.05,,S
6,0,3,"Moran, Mr. James",male,,0,0,330877,8.4583,,Q
7,0,1,"McCarthy, Mr. Timothy J",male,54,0,0,17463,51.8625,E46,S
8,0,3,"Palsson, Master. Gosta Leonard",male,2,3,1,349909,21.075,,S
.../...
Vous remarquez que les champs sont bien séparés par des , et que la première ligne contient le nom des colonnes. Deux questions se posent:
Les champs peuvent-ils être séparés par un autre caractère que la virgule dans un fichier csv ?
Oui vous pouvez mettre le caractère que vous voulez pour séparer les champs dans un csv: le tout sera (pour les utilisateurs du fichier) d’indiquer ce caractère lors de la lecture de la table (la fonction de lecture ne pourra pas le deviner). Par exemple le ; qui apparaîtra souvent. Un fichier portera, le plus souvent, l’extension .csv, mais vous allez pouvoir trouver des .tsv.
Trouve-t-on toujours les noms des colonnes en première ligne des fichiers .csv ?
Non ce n’est pas obligatoire ! Certains fichiers ne comporteront pas d’entête, certains fichiers auront des lignes de commentaires en début de fichier suivies ou non du la ligne d’entête … oui vous commencez à vous dire qu’il va falloir bien indiquer tout cela lors de la lecture du fichier
(la fonction de lecture aura un comportement par défaut que vous pourrez paramétrer)
Uniquement pour les avancés, deux autres remarques:
Certains champs - comme "Braund, Mr. Owen Harris" - sont mis dans des chaînes entre "" et les autres champs non. Pourquoi ? Est-ce parce qu’il y a des espaces ? Non, une fonction sait prendre tous les caractères entre deux , … heu … tous ? non ! pas le séparateur lui-même (ici la ,), bien sûr ! Les champs qui contiennent le séparateur doivent du coup être protégés, c’est le propos de ces "".
Une dernière chose ? oui il n’y a PAS d’espace autour des virgules … pourquoi ? et bien parce que ce n’est pas un caractère séparateur mais un vrai caractère, et il sera pris dans le champ ! Et si on avait mis des espace après les séparateurs (comme on le fait quand on écrit) ?
1 ,0 ,3 ,"Braund, Mr. Owen Harris",male ,22 ,1 ,0 ,A/5 21171 ,7.25 , ,S\
Là monsieur “Braund, Mr. Owen Harris” aura pour PassengerId le nombre 1 suivi d’un espace (“1 “) quel drôle de nombre, la fonction qui va le traiter pourra-t-elle y voir un nombre ? sûrement pas, elle verra une chaîne de caractères contenant un 1 et un espace.
Bien sûr il va exister des (tas de) paramètres pour régler ce genre de petits problèmes, là ce sera skipinitialspace qui est à False par défaut et que donc vous passerez avec la valeur True pour Skip spaces after delimiter.
Un constat: numpy ne comporte pas de fonction pour lire ces tables !
Ce rôle est pris depuis 2008 par une autre librairie qui s’appelle pandas et qui repose entièrement sur numpy: toutes les données que vous allez manipuler en pandas sont en mémoire des tableaux np.ndarray.
pandas va vous en faciliter l’utilisation en leur donnant un type évolué de table de données pandas.DataFrame. Un autre type permettra de gérer les séries le pandas.Series.
Une dernière chose à préciser, si le langage Python favorise la simplicité, l’uniformité et la lisibilité du code sur son efficacité … pandas comme numpy va favoriser très clairement l’efficacité au détriment du reste. Ou dit plus simplement: “Ne vous attendez pas au même niveau de maturité et de cohérence dans numpy et pandas que celui que vous avez dans Python”
Ils n’ont pas trouvé leur BDFL comme Python avec Guido van Rossum.
lisons une table de données (pandas.read_csv)¶
Sans plus attendre on importe la librairie pandas (son petit nom standard est pd) et on lit notre table du titanic dans une variable df (pour dataframe, c’est un nom très couramment utilisé)!
Avec quelle fonction lisons-nous le fichier ? Avec la fonction pandas.read_csv !
Vous n’avez pas pandas ? Qu’à cela ne tienne ! Importez-le à partir d’un terminal (ou du notebook si vous savez le faire).
pip install pandas
import pandas as pd
Pour les avancés, les nouveautés des différentes versions sorties (releases) sont ici https://pandas.pydata.org/docs/whatsnew/index.html. Si nous voulons savoir le numéro de version d’une librairie, il faut regarder l’attribut __version__ de la librairie, donc ici pandas.__version__ (enfin pd.__version__, mais on a choisi de toujours mettre le nom complet de la librairie dans les notebooks).
pd.__version__
'1.3.1'
Au passage importons donc numpy puisque les deux librairies sont très liées …
import numpy as np
Plutôt que de détailler les fonctionnalités de pandas, partons d’un exemple existant et lisons la table des passagers du titanic:
df0 = pd.read_csv(file)
Regardons les quelques premières lignes (le header) de la table avec la méthode pandas.DataFrame.head qui par défaut en affiche 5.
df0.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
Nous remarquons là une chose importante qui va être la clé pour comprendre l’intérêt de pandas: les lignes et les colonnes sont indexées.
la notion d’index dans les bases de données¶
En guise de digression, et pour bien comprendre cette histoire d’index, on va parler d’une notion qui est bien plus ancienne que pandas, et qu’on a inventée au départ dans le contexte des bases de données relationnelles.
L’idée tourne toujours autour de cette affaire de recherche dans les listes, qui est très inefficace. C’est comme dans les bibliothèques (à l’époque où elles existaient encore sous une forme physique) : lorsque vous cherchez un livre vous n’allez pas reparcourir tous les rayons jusqu’à trouver le livre qui vous intéresse; non, vous allez demander au guichet, où l’on dispose d’un index qui vous indique où se trouve le livre; c’est quand même beaucoup plus rapide !
C’est un peu pareil avec les données; imaginez que vous avez des données à propos de 10 millions de personnes; si vous vous contentez de modéliser ça sous la forme d’une liste de personnes, il vous faut en moyenne 5 millions d’essais pour localiser quelqu’un.
La technique de l’index consiste simplement à trouver une caractéristique qui identifie la personne de manière unique (disons le numéro de sécurité sociale), et à calculer un index qui permette un accès rapide - pour ça on utilise une table de hachage, exactement comme avec les dictionnaires Python.
De cette façon, l’opération qui consiste à localiser (les informations concernant) une personne, à partir de son numéro de sécu, peut être en grossière approximation considérée comme en temps constant.
les tables pandas sont indexées¶
Fort de cette expérience avec les bases de données, pandas a choisi d’indexer ses tables, dans les deux directions : ligne et colonne.
Le travail de pandas va consister à rendre les opérations sur ces index les plus efficaces possible
(on pourrait discuter de l’intérêt d’indexer les colonnes qui sont généralement moins nombreuses, disons que ça rend le design plus homogène, et aussi, qui peut le plus peut le moins, ça ne nuit pas du tout d’indexer les colonnes)
# revenons à nos moutons
df0.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
Les index apparaissent en gras dans la sortie de head(), si bien que sur notre exemple, on voit que :
les colonnes ont été indexées par leur nom, naturellement,
et que, comme nous n’avons rien précisé de particulier, les lignes ont, elles, été indexées par leur indice
i.e. une simple numérotation à partir de 0
Mais si vous regardez bien le contenu de notre dataframe, il y a là une colonne PassengerId; rien qu’avec le nom, on devine que cette colonne contient effectivement un identifiant unique pour chaque passager; (c’est d’ailleurs presque toujours le cas dans les bases de données aussi, vous allez trouver des noms de colonne en PersonId, BookId, etc…);
Du coup, ça devient un réflexe que d’utiliser cette colonne-là comme clé pour l’index des lignes; et pour faire ça il suffit de l’indiquer à pandas, comme ceci :
# on charge le même fichier
# on choisit la colonne qui sert d'index
df = pd.read_csv(file, index_col='PassengerId')
df.head()
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
On a vu que ce n’était pas indispensable, mais c’est une bonne pratique que de choisir comme index une colonne qui puisse jouer ce rôle d’identifiant unique.
le type d’une table (pandas.DataFrame)¶
Maintenant regardons d’un peu plus près les attributs de cette table.
Nous allons comprendre à travers cette table du Titanic comment sont composées les tables, et quels sont leurs attributs utiles (à notre niveau) et comment les utiliser pour exploiter nos données.
Si vous êtes familier de Python, le premier réflexe est d’afficher le type de la table; c’est utile de connaitre le type des objets, car c’est le type qui détermine les opérations qu’on a le droit de faire sur ces objets;
type(df)
pandas.core.frame.DataFrame
Le type de df est pandas.core.frame.DataFrame, un nom plus court pour ce type est pandas.DataFrame.
la dimension et la forme de la table (ndim, shape)¶
Quelle est la dimension et la forme de cette table ?
on va retrouver les attributs classiques que nous avions en numpy soit ndim, shape… qui seront là des noms de méthodes des dataframes.
# une dataframe est toujours de dimension 2
df.ndim
2
Notre table est une pandas.DataFrame de dimension 2, on s’y attendait.
print(df.shape)
(891, 11)
Sa forme est 891 lignes et 11 colonnes.
Nous avons dit que pandas est fondé sur numpy. Donc où numpy intervient-il ? Vous l’avez compris bien sûr : il va s’occuper du stockage et de la gestion du tableau de dimension 2 sous-jacent.
Et pandas ? il va nous décorer ce tableau avec des fonctions très pratiques, et de plus haut-niveau que numpy, pour manipuler plus facilement qu’en numpy notre table de lignes et de colonnes, de manière à faire du data-science.
les colonnes de la table¶
Quels sont les noms des colonnes ?
Ils sont accessibles par la property pandas.DataFrame.columns qui va vous renvoyer un objet de type … de type ? oui Index ! puisque les noms des colonnes sont les index des colonnes !
df.columns
Index(['Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket',
'Fare', 'Cabin', 'Embarked'],
dtype='object')
Oui je sais, on voit le type dtype='object' des éléments mais nous parlerons des types après, on ne peut pas tout faire en même temps ! et il va falloir comprendre de petites choses avant.
Qui dit index dit accès, donc nous allons bien pouvoir accéder aux colonnes de la table.
Les colonnes ont un traitement un peu priviligié en pandas. En fait une table pandas est un peu comme un dictionnaire où les clés sont les noms des colonnes, et où les valeurs sont les colonnes.
Un peu comme un dictionnaire ? la dataframe ? Donc nous pouvons accéder à une colonne par sa clé, par exemple, Age ou encore Name !
df['Age']
PassengerId
1 22.0
2 38.0
3 26.0
4 35.0
5 35.0
...
887 27.0
888 19.0
889 NaN
890 26.0
891 32.0
Name: Age, Length: 891, dtype: float64
C’est bien la colonne des 891 âges. Et là on peut regarder le type des éléments, ce sont des float64, pas de problème, les âges ne sont pas toujours des nombres entiers.
Nous allons regarder quel est le type de la structure de donnée de colonnes.
le type d’une colonne (pandas.Series)¶
Reprenons notre dataframe favorite, des malheureux passagers du Titanic, et regardons le type utilisé par pandas pour la structure de donnée de colonne.
type(df['Age'])
pandas.core.series.Series
Voilà, qu’apparaît le second type de pandas, celui des Series … Une colonne est une série de données ! Le nom de la colonne est la clé dans un pseudo-dictionnaire pour accéder à cette série de données ! On commence à y voir un peu plus clair !
Je dis pseudo parce que pandas accepte que plusieurs colonnes portent le même nom. Et si vous demandez d’aller chercher les colonnes correspondant à cette clé … il vous les donne toutes.
pandas ne va pas imposer que les clés des lignes ou des colonnes soient uniques. Lors de la recherche d’une clé non unique, il vous donnera toutes les entrées correspondantes.
df1 = pd.DataFrame(np.array([[1, 2, 3, 4], [5, 6, 7, 8]]),
index=(1, 1),
columns=('a', 'a', 'b', 'c'))
df1['a']
| a | a | |
|---|---|---|
| 1 | 1 | 2 |
| 1 | 5 | 6 |
Que peut-on faire comme calculs sur nos colonnes ? Des tas de choses dont nous allons voir quelques exemples.
les petites fonctions statistiques sur les colonnes¶
Que peut-on faire sur une série de valeurs ?
Si les valeurs sont quantitatives (comme l’âge) on peut essayer de mieux décrire cette colonne en calculant des fonctions comme le minimum, le maximun, la moyenne, l’écart-type, les quartiles …
Appliquons le à la colonne des âges :
df['Age'].describe()
count 714.000000
mean 29.699118
std 14.526497
min 0.420000
25% 20.125000
50% 28.000000
75% 38.000000
max 80.000000
Name: Age, dtype: float64
Ces calculs sont regroupées dans une méthode appelée pandas.Series.describe. On y voit que le plus jeune avait dans les 5 mois et le plus vieux 80 ans, que la moyenne d’âge est de presque 30 ans, que 75% des passagers avaient en dessous de 38 ans.
Si la valeur est qualitatives, ou catégorielle (comme le genre), on peut calculer le nombre des valeurs différentes et les fréquences de chacune de ces valeurs.
df['Sex'].value_counts()
male 577
female 314
Name: Sex, dtype: int64
Vous remarquez que les fonctions appliquées sont naturellement des fonctions vectorisées i.e. qui s’appliquent à tout un tableau à la fois (ici à toute une colonne à la fois).
programmation vectorielle - conditions sur les éléments d’une colonne¶
Revenons à l’âge des passagers. Et si je voulais savoir, combien de passager avaient moins de 12 ans ? ou combien avaient plus de 65 ?
Rappelez-vous qu’en numpy on fait de la programmation vectorielle, i.e. on applique les fonctions à tout un tableau ou à tout un sous-tableau, et non en itérant sur les valeurs avec un for-Python ! et cela par souci d’efficacité !
Il faut faire pareil en pandas: éviter les itérations sur les données, utiliser les fonctions vectorisées; ainsi l’itération sur les éléments sera faite dans le langage dans lequel sont écrits numpy et pandas, rapide et proche de la mémoire.
Voici un premier exemple, avec les opérateurs de comparaison: ils s’appliquent à toute la colonne. Ainsi pour les moins de 12 ans je vais écrire simplement
df['Age'] < 12
et avec cette expression, je récupère un tableau de booléens qui me disent, pour chaque valeur de la colonne, comment elle répond à cette condition; en fait cette expression va me retourner un objet Series (comme une colonne)
Ce tableau contient des False et des True. Et comment puis-je compter le nombre de résultats True qui me donnera le nombre d’enfants ?
On le fait. Alors il va y avoir plusieurs manières.
(i)Je peux faire la somme de toutes les réponses (les True seront des 1 et les False des 0, c’est très pratique les booléens);
(ii) je peux aussi utiliser la fonction value_counts;
Et il y a sûrement d’autres manières de faire … On va montrer les deux (essayez de faire %timeit sur les deux lignes de code si vous voulez en comparer les performances):
# value_counts marche avec toutes les Series
# pour compter le nombre d'occurrence des
# différentes valeurs trouvées dans la colonne
(df['Age']<12).value_counts()
False 823
True 68
Name: Age, dtype: int64
Donc on a 68 passagers de moins de 12 ans dans cette table.
# on peut faire la somme lorsqu'on
# sait qu'on n'a que des booléens
(df['Age'] < 12).sum()
68
Oui, voilà la même chose calculée différemment.
Est-ce qu’on peut dire qu’il y a 823 passagers de plus de 12 ans (attention piège …) ?
En fait on ne peut pas le dire en regardant les âges. Pourquoi ? Affichez la table des âges.
df['Age']
PassengerId
1 22.0
2 38.0
3 26.0
4 35.0
5 35.0
...
887 27.0
888 19.0
889 NaN
890 26.0
891 32.0
Name: Age, Length: 891, dtype: float64
Effectivement on remarque que le passager 889 à un âge un peu particulier qui est NaN ! Allons-y voir de plus prés ! Quel est donc cet étrange Age et son type ?
les valeurs manquantes, NA (non-available) ou NaN (not-a-number)¶
Donc nous venons de nous rendre compte que dans la colonne Age le passager d’index 889 a un NaN et pas un nombre flottant ! Élucidons vite ce mystère !
Affichons cet élément.
df['Age'][889]
nan
C’est bien toujours un nan (en fait np.nan)
Regardons le type de l’élément nan … heu … pandas a dit float64, on pourrait peut-être le croire ! oui mais vérifions quand même:
type(df['Age'][889])
numpy.float64
Oh c’est bien un flottant ! Mais quel est donc de drôle de flottant ? Une idée ?
Et bien c’est le flottant qui signifie Not A Number parce que là, tout simplement, cette table ne connait pas l’âge de cette personne et elle l’indique avec cette valeur nan de type flottant.
Regardons dans le fichier csv comment est indiquée cette absence de valeur … une idée ?
889,0,3,"Johnston, Miss. Catherine Helen ""Carrie""",female,,1,2,W./C. 6607,23.45,,S
Alors cette absence de valeur ? ahhh ce sont tout simplement ,, deux virgules qui se suivent avec rien entre elles, pas bête ! Cette valeur est aussi appelée NA pour Not Available.
Ainsi nous ne connaissons pas l’âge de certains passagers. Pouvons-nous dire combien il nous manque d’informations dans la colonne des âges ?
Pour cela, on peut utiliser (par exemple) la fonction pandas.Series.notna qui va nous rendre une colonne de True et de False et tout simplement - comme pour le test de l’âge inférieur à 12 ans ci-dessus - on va compter les True (qui sont donc les passagers pour lesquels la valeur de l’âge est notna !).
np.sum(df['Age'].notna())
714
On connait l’âge de 714 passagers.
Pour combien de passagers nous manque-t-il l’information d’âge ? On a l’embarras du choix …
Soit on utilise 714 qu’on retranche au nombre total de passagers (qui est le nombre de lignes ou encore la longueur
lende la table).Soit on prend la négation de la colonne de booléen (
np.logical_notor~) et on compte lesTrue.Soit on utilise la fonction
pandas.Series.isnaqui nous renvoie une colonne deTrueetFalseet on compte le nombre deTrue.Soit on utilise
pandas.value_countssur le tableau de booléens…
je vous montre l’une des solutions les plus rapides: compter le nombre de True dans la colonne résultant du test.
(df['Age'].isna()).sum()
177
Donc 177 informations sur l’âge sont manquantes.
Si vous voulions faires des opérations booléennes entre les colonnes, il faut utiliser les fonctions dédiées np.logical_not, np.logical_and, np.logical_or… ou leur contrepartie resp. ~, & et |.
np.sum(np.logical_not(df['Age'].isna()))
714
Reprenons dans le fichier csv la passagère 889.
889,0,3,"Johnston, Miss. Catherine Helen ""Carrie""",female,,1,2,W./C. 6607,23.45,,S
On remarque que la valeur de son avant-dernière colonne n’est pas non plus indiquée. Regardons alors quelle est l’avant dernière colonne et accédons à sa série de valeurs. Les colonnes sont données par le champ columns et l’indice de l’avant-dernier sera -2.
df.columns[-2]
'Cabin'
Regardons la colonne des Cabin.
df['Cabin']
PassengerId
1 NaN
2 C85
3 NaN
4 C123
5 NaN
...
887 NaN
888 B42
889 NaN
890 C148
891 NaN
Name: Cabin, Length: 891, dtype: object
Vous remarquez que dans ce cas là aussi, la valeur manquante est indiquée par un NaN, avec un type des éléments object (on reviendra plus tard sur les types).
À vous de jouer. Calculez le nombre de valeurs manquantes dans la colonne des numéros des cabines.
# votre code ici
Une pandas.DataFrame a aussi des lignes, nous allons les voir dans la section suivante…
les lignes de la table¶
index et indice¶
On a vu que pandas tend à favoriser l’utilisation des index.
Il est important avec pandas de bien faire la différence entre index et indice :
les index peuvent être un peu ce qu’on veut, ici on a des entiers, ça pourrait être aussi bien des chaînes de caractères
les indices sont **toujours(( des entiers qui commencent à 0 (comme les indices des listes et des tableau)
Une autre différence importante, c’est que l’index appartient à la ligne, et sera préservé par exemple lors d’un tri ou d’une insertion; alors qu’au contraire bien sûr, les indices eux se retrouvent tout chamboulés
Dans l’état actuel de la dataframe, l’index (qui coincide ici avec PassengerId, et qui commence à 1), est très voisin de l’indice (qui commence toujours à 0).
Du coup les deux sont très proches, et on risque de s’emmêler; pour rendre les choses plus claires, nous allons trier la table - disons selon les âges des passager.
# on recharge la table
df = pd.read_csv("titanic.csv").set_index('PassengerId')
# avant de trier: la première ligne a
# son indice = 0 (c'est la premiere)
# son index = 1 (PassengerId)
df.head()
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
# je trie la dataframe (sans faire de copie)
# on reparlera plus longuement des méthodes de tri plus tard
df.sort_values(by='Age', inplace=True)
df.head()
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||
| 804 | 1 | 3 | Thomas, Master. Assad Alexander | male | 0.42 | 0 | 1 | 2625 | 8.5167 | NaN | C |
| 756 | 1 | 2 | Hamalainen, Master. Viljo | male | 0.67 | 1 | 1 | 250649 | 14.5000 | NaN | S |
| 645 | 1 | 3 | Baclini, Miss. Eugenie | female | 0.75 | 2 | 1 | 2666 | 19.2583 | NaN | C |
| 470 | 1 | 3 | Baclini, Miss. Helene Barbara | female | 0.75 | 2 | 1 | 2666 | 19.2583 | NaN | C |
| 79 | 1 | 2 | Caldwell, Master. Alden Gates | male | 0.83 | 0 | 2 | 248738 | 29.0000 | NaN | S |
Dans cette version triée, la ligne correspondant à Miss Eugenie Baclini a pour index 645, et pour indice 2.
contenu de l’index¶
Comment connaître les index des lignes ?
Ils sont accessibles grâce à la méthode pandas.DataFrame.index.
# comme pour df.columns, le résultat est un Index
df.index
Int64Index([804, 756, 645, 470, 79, 832, 306, 828, 382, 165,
...
833, 838, 840, 847, 850, 860, 864, 869, 879, 889],
dtype='int64', name='PassengerId', length=891)
# par exemple pour savoir s'il existe
# dans la table un PassengerId qui vaut 645
645 in df.index
True
1000 in df.index
False
pour les curieux, qui s’interrogeraient sur la relation entre Index et Int64Index :
il se trouve que dans cette dataframe, l’index a des valeurs entières,
c’est pourquoipandasa choisi pour lui le typeInt64Indexon peut vérifier que cet objet est bien aussi un
Index:
# Int64Index est bien une sous-classe de Index
issubclass(pd.Int64Index, pd.Index)
True
# on peut le vérifer aussi comme ceci,
# de manière équivalente
isinstance(df.index, pd.Index)
True
accéder aux lignes et cellules : utilisez loc¶
La méthode recommandée pour accéder à une ligne, (ou à une cellule d’ailleurs, on en reparlera), consiste à utiliser les index.
La philosophie de pandas, de façon générale, consiste à favoriser les accès par index - par opposition aux accès par indices.
Les accès par index se font au travers de loc; voici comment ça se présente :
# pour accéder à la personne dont le PassengerId est 889
df.loc[889]
Survived 0
Pclass 3
Name Johnston, Miss. Catherine Helen "Carrie"
Sex female
Age NaN
SibSp 1
Parch 2
Ticket W./C. 6607
Fare 23.45
Cabin NaN
Embarked S
Name: 889, dtype: object
# remarquez que le résultat est, à nouveau, de type `Series`
type(df.loc[889])
pandas.core.series.Series
La property loc permet aussi d’accéder aux cellules :
df.loc[889, 'Pclass'] # le nom de la cellule est en seconde position
3
RÉSUMÉ pour les accès en lecture
la forme
df['Age']fonctionne bien pour accéder aux colonnesla forme
df.loc[889]permet d’accéder aux lignes d’après leur indexpour accéder à une cellule, on utilise
df.loc[889, 'Age']oudf['Age'][889]
sauf que les deux formes ont leurs indices renversés; et de plus l’un utilise une virgule et l’autre des crochets !
df[colonne][ligne]etdf.loc[ligne, colonne]
c’est parmi les choses assez confusantes au sujet de pandas
On décompose l’expression df['Age'][889] (remarquez ici le chaînage des index [][]) :
on accède à la colonne d’index
Agede la DataFramedfcet accès rend la série (
pandas.Series) représentant la colonnedf['Age']on accède à l’index
889de cette série
RÉSUMÉ à propos des types
les tables pandas sont représentées par le type
DataFrameune dataframe a un index pour accéder aux colonnes (
df.columns)
et un index pour accéder aux lignes (df.index)
ces deux objets sont de typeIndexune colonne, ou une ligne, sont de type
Series- qui correspond si on veut à des données en 1 seule dimension
modifier une cellule¶
MISE EN GARDE
Pour modifier (écrire dans) une cellule, on pourrait penser écrire du code de ce genre
~~
df.loc[889]['Age'] = 10~~
ou encore~~
df['Age'][889] = 10~~
il ne faut PAS le faire; si vous essayez l’une ou l’autre de ces formes, vous obtenez un gros avertissement (A value is trying to be set on a copy of a slice from a DataFrame) et parfois miraculeusement ça marche tout de même, mais c’est accidentel !
# df['Age'][889] = 10
La bonne méthode, je vous engage à en prendre l’habitude, consiste à utiliser cet idiome :
df.loc[889, 'Age'] = 10
vous remarquez qu’ici
on a indexé l’objet
df.locau travers d’un tuple
(souvenez-vous qu’en Python889, 'Age'est un tuple),et non pas en indexant deux fois
(quand on utilise une des deux formes à éviter
on indexe une première fois par889
puis on indexe le résultat par'Age'
en anglais on parle de chained indexing)
df.loc[889, 'Age'] = 10
# pour vérifier
df.loc[889, 'Age']
# ou df['Age'][889] puisque vous ne modifiez pas !
10.0
accès par indices : iloc et iat¶
Bien que la plupart du temps on utilise les index pour accéder aux contenus, il se trouve parfois des situations où l’accès par indices peut être ponctuellement intéressant.
Et en fait c’est très simple : pour utiliser des indices plutôt que des index, il sufit de remplacer loc par iloc
Pour s’en souvenir, on peut se rappeler que le i veut dire integer, donc indices et non pas index
# le contexte
df.head()
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||
| 804 | 1 | 3 | Thomas, Master. Assad Alexander | male | 0.42 | 0 | 1 | 2625 | 8.5167 | NaN | C |
| 756 | 1 | 2 | Hamalainen, Master. Viljo | male | 0.67 | 1 | 1 | 250649 | 14.5000 | NaN | S |
| 645 | 1 | 3 | Baclini, Miss. Eugenie | female | 0.75 | 2 | 1 | 2666 | 19.2583 | NaN | C |
| 470 | 1 | 3 | Baclini, Miss. Helene Barbara | female | 0.75 | 2 | 1 | 2666 | 19.2583 | NaN | C |
| 79 | 1 | 2 | Caldwell, Master. Alden Gates | male | 0.83 | 0 | 2 | 248738 | 29.0000 | NaN | S |
# on va upgrader un passager qui est en 3-ème classe
# ligne d'indice 2 = PassengerId 645
# colonne d'indice 1 = PClass
df.iloc[2, 1]
3
# si vous voulez coder par indices, utilisez iloc
# regardez la nouvelle valeur de Pclass sur le passager 645
df.iloc[2, 1] = 2
df.head()
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||
| 804 | 1 | 3 | Thomas, Master. Assad Alexander | male | 0.42 | 0 | 1 | 2625 | 8.5167 | NaN | C |
| 756 | 1 | 2 | Hamalainen, Master. Viljo | male | 0.67 | 1 | 1 | 250649 | 14.5000 | NaN | S |
| 645 | 1 | 2 | Baclini, Miss. Eugenie | female | 0.75 | 2 | 1 | 2666 | 19.2583 | NaN | C |
| 470 | 1 | 3 | Baclini, Miss. Helene Barbara | female | 0.75 | 2 | 1 | 2666 | 19.2583 | NaN | C |
| 79 | 1 | 2 | Caldwell, Master. Alden Gates | male | 0.83 | 0 | 2 | 248738 | 29.0000 | NaN | S |
exercice¶
lecture d’un petit-titanic¶
Là aussi deux niveaux d’exercices, le premier pour les débutants et le second pour les avancés (ou les débutants une fois compris le premier).
Le fichier petit-titanic.csv contient les 10 premières lignes de passagers.
file = 'petit-titanic.csv'
# pour voir le contenu de ce fichier
with open("petit-titanic.csv") as feed:
print(feed.read(), end="")
1;0;3;"Braund, Mr. Owen Harris";male;22;1;0;A/5 21171;7.25;;S
2;1;1;"Cumings, Mrs. John Bradley (Florence Briggs Thayer)";female;38;1;0;PC 17599;71.2833;C85;C
3;1;3;"Heikkinen, Miss. Laina";female;26;0;0;STON/O2. 3101282;7.925;;S
4;1;1;"Futrelle, Mrs. Jacques Heath (Lily May Peel)";female;35;1;0;113803;53.1;C123;S
5;0;3;"Allen, Mr. William Henry";male;35;0;0;373450;8.05;;S
6;0;3;"Moran, Mr. James";male;;0;0;330877;8.4583;;Q
7;0;1;"McCarthy, Mr. Timothy J";male;54;0;0;17463;51.8625;E46;S
8;0;3;"Palsson, Master. Gosta Leonard";male;2;3;1;349909;21.075;;S
9;1;3;"Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg)";female;27;0;2;347742;11.1333;;S
10;1;2;"Nasser, Mrs. Nicholas (Adele Achem)";female;14;1;0;237736;30.0708;;C
le petit-titanic pas à pas¶
Pas à pas
Lisez le fichier avec les paramètres par défaut de
pd.read_csvAfficher les quelques (5) premières lignes. Cette data-frame vous-convient-elle ? non !!
Déjouer les deux pièges ! En cas de problème ? Lisez le help !
Combien y-a-t-il de colonnes ? et de lignes ?
Afficher l’index des colonnes. Changez le en mettant des noms à vos colonnes
Afficher l’index des lignes. Changer le en mettant la colonnes des identificateurs des passagers
Comptez le nombre de valeurs manquantes dans toutes les colonnes de data-frame
# décommentez pour lire le help de read_csv:
#pd.read_csv?
# votre code ici
petit_df = ...
# vous devez retrouver ces passagers
# avec peut être des différences au niveau des colonnes (noms et nombre)
df.sort_index().head(10)
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| 6 | 0 | 3 | Moran, Mr. James | male | NaN | 0 | 0 | 330877 | 8.4583 | NaN | Q |
| 7 | 0 | 1 | McCarthy, Mr. Timothy J | male | 54.0 | 0 | 0 | 17463 | 51.8625 | E46 | S |
| 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2.0 | 3 | 1 | 349909 | 21.0750 | NaN | S |
| 9 | 1 | 3 | Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) | female | 27.0 | 0 | 2 | 347742 | 11.1333 | NaN | S |
| 10 | 1 | 2 | Nasser, Mrs. Nicholas (Adele Achem) | female | 14.0 | 1 | 0 | 237736 | 30.0708 | NaN | C |
le petit-titanic en un seul coup¶
Passez les bons paramètres à pandas.read_csv de manière à ce que le test indiqué ci-dessous renvoie un tableau avec majoritairement des True.
Mais deux colonnes vont néanmoins contenir quelques False. Comprenez-vous pourquoi ?
# votre code ici
petit_df = ...
# pour vérifier votre code, ceci doit renvoyer un tableau avec majoritairement des 'True'
# on utilise sort_index() pour remettre dans le bon ordre (on les avait triés par age)
# vous remarquez quelque chose dans loc ? le passager d'index de ligne 10 est ? oui il est compris
df.sort_index().loc[:10, :] == petit_df
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||
| 1 | False | False | False | False | False | False | False | False | False | False | False |
| 2 | False | False | False | False | False | False | False | False | False | False | False |
| 3 | False | False | False | False | False | False | False | False | False | False | False |
| 4 | False | False | False | False | False | False | False | False | False | False | False |
| 5 | False | False | False | False | False | False | False | False | False | False | False |
| 6 | False | False | False | False | False | False | False | False | False | False | False |
| 7 | False | False | False | False | False | False | False | False | False | False | False |
| 8 | False | False | False | False | False | False | False | False | False | False | False |
| 9 | False | False | False | False | False | False | False | False | False | False | False |
| 10 | False | False | False | False | False | False | False | False | False | False | False |
# hints pour comparer vous devez retrouver ceci
# mais avec quelques colonnes en moins
df.sort_index().head(10)
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PassengerId | |||||||||||
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| 6 | 0 | 3 | Moran, Mr. James | male | NaN | 0 | 0 | 330877 | 8.4583 | NaN | Q |
| 7 | 0 | 1 | McCarthy, Mr. Timothy J | male | 54.0 | 0 | 0 | 17463 | 51.8625 | E46 | S |
| 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2.0 | 3 | 1 | 349909 | 21.0750 | NaN | S |
| 9 | 1 | 3 | Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg) | female | 27.0 | 0 | 2 | 347742 | 11.1333 | NaN | S |
| 10 | 1 | 2 | Nasser, Mrs. Nicholas (Adele Achem) | female | 14.0 | 1 | 0 | 237736 | 30.0708 | NaN | C |